


Reward models (RMs) are fundamental to the development of today’s large language models (LLMs), providing the critical feedback signals needed to align them with human goals. These models, trained to predict human preferences, have become standard components in the training pipelines that produce the state-of-the-art LLMs we interact with daily.
Our favorite topic - LLM-as-a-judge - has emerged as a promising direction for scaling evaluation and feedback generation beyond human labelers. The ability of LLMs to provide detailed critiques and evaluations across diverse tasks has made them increasingly attractive to assess generative AI applications both pre-deployment and in production.
These two research directions - reward modeling and LLM-based evaluation - have recently begun to merge, as researchers explore ways to incorporate LLMs' reasoning capabilities into reward model architectures. Recent literature investigates whether reward models that can generate detailed critiques and explanations, similar to LLM judges, might offer advantages over traditional reward modeling approaches. Let's examine the empirical evidence on effectiveness, limitations and optimal use cases for these hybrid approaches.

Traditional Reward Models in RLHF
Reward models are a critical piece of the post-training process for LLMs. These models are trained on human feedback data to predict human preferences, such as safety considerations and more nuanced aspects of behavior, by learning to evaluate and rank different outputs from a language model. Then, a reinforcement learning algorithm, like Proximal Policy Optimization (PPO) is used to tune the base LLM by maximizing the rewards predicted by the trained reward model. This process, known as Reinforcement Learning from Human Feedback (RLHF), helps guide policy updates for the LLM to better align with human preferences and improve performance.
RLHF has been a pivotal paradigm for aligning LLMs to human preferences and a large part of the performance and breakthrough success of popular LLM applications like ChatGPT.
However, gathering high-quality, human preference labels is expensive, time-consuming and resource-intensive, making it challenging to scale effectively. These challenges have motivated the adoption of LLMs that can simulate human evaluation processes more efficiently and consistently. Modern LLMs have been shown to reflect a high degree of alignment with human judgment (Giraldi et al. 2023), suggesting that LLM-generated preference labels might be effective as substitutes to human labels.

Reinforcement Learning from AI Feedback
Reinforcement Learning from AI Feedback (RLAIF), introduced by Anthropic, is a paradigm where the reward model is trained on a hybrid of human and AI preferences generated by an off-the-shelf LLM. Together with a predefined constitution (broadly guiding the model to to be helpful, honest, and harmless) with behavioral constraints, their final policy achieved better harmlessness scores than RLHF baselines while maintaining comparable helpfulness.

*Elo scores here are used to rank AI models based on relative performance in the two given areas. Higher scores mean the model is better at a given trait.
Lee et al. (2023) provided additional validation, finding comparable human preference ratings between RLAIF and RLHF policies across tasks including summarization and dialogue generation.

Despite its advantages, RLAIF faces several challenges. AI-generated feedback may inherit biases from the base models, potentially creating feedback loops that perpetuate errors if not carefully managed. The absence of direct human oversight can also result in a lack of nuanced understanding, potentially missing contextual insights. Developing sophisticated reward models that accurately mimic human preferences remains a complex challenge. This has motivated the development of techniques we’ll explore below - like the use of synthetic critiques, to combine the scalability of AI feedback with stronger quality guarantees.
LLM-as-a-Judge vs. Reward Model
LLM-as-a-judge approaches use the full reasoning capabilities of LLMs to perform detailed evaluations of responses. While following user-provided rubrics, these models employ chain-of-thought reasoning, considering multiple aspects of quality and explaining their scoring decisions. This explicit reasoning process helps improve transparency and allows for more nuanced evaluation compared to simpler scoring methods, though usually at the cost of increased computational overhead.
Traditional reward models typically employ specialized architectures optimized for efficient preference prediction, such as classification heads to provide direct scoring based on specific criteria. This approach enables fast, consistent preference learning and scales well to large datasets. While highly efficient, these models can be vulnerable to data artifacts (superficial patterns in training data that don’t genuinely represent human preferences) and may struggle to capture complex aspects of human preferences that require deeper reasoning - leading to potential misalignment between model predictions and human preferences.

Incorporating Critiques in Reward Models
By integrating critiques, reward models can simulate human-like evaluation, providing more nuanced assessments of LLM outputs. This approach leverages the language generation capabilities of LLMs to produce critiques that guide the learning process more effectively. Critiques improve interpretability during model training and robustness to adversarial samples.
Critique-based reward models offer several advantages over traditional reward models. They provide richer feedback, allowing for more comprehensive evaluations beyond simple scoring. Their deep analysis helps address biases and improves the generalization of LLMs by focusing on reasoning and context (see Figure 8). Additionally, critiques can enhance data efficiency, reducing the need for extensive human annotation by simulating detailed human feedback.
In the literature to date, synthetic critiques have largely been generated using off-the-shelf LLMs, making this an accessible, scalable approach to alignment. An open research question is whether specialized LLM judges could generate higher-quality critiques than general-purpose models, and how this might improve alignment outcomes. Looking ahead, we may see next-generation reward models themselves incorporate the sophisticated reasoning capabilities of LLM judges. The potential of critiques has been recognized by a benchmark called CriticBench (Lan et al., 2024) that measures the quality of critiques along four dimensions:
- Feedback: Evaluates how well the critique identifies and addresses specific issues in the target response.
- Comparison: Assesses the critique's ability to compare different responses effectively, highlighting relative strengths and weaknesses.
- Refinement: Measures how the critique suggests improvements, guiding towards a more accurate or useful response.
- Meta-feedback: Evaluates the coherence, structure, and appropriateness of the feedback given.

Synthetic Critiques model
Ye et al. (2024) introduced the Synthetic Critiques model that employs synthetic, LLM-generated
critiques to provide richer feedback for reward models to assess and generate scores. This approach is cost-effective and scalable, as it uses model-generated critiques to evaluate aspects such as correctness and style. Results seemed to indicate that high-quality synthetic critiques improve the performance of the reward models and conversely that low-quality critiques deteriorate performance.
The training process prompts weaker and stronger LLMs, such as LLaMA2-7B-Chat, Mixtral-8x7B-Instruct, and GPT-4 Turbo, to generate synthetic critiques for each prompt-completion pair. Reward models, conditioned on these synthetic critiques, then predict scalar rewards for each output.
Critique-out-loud model
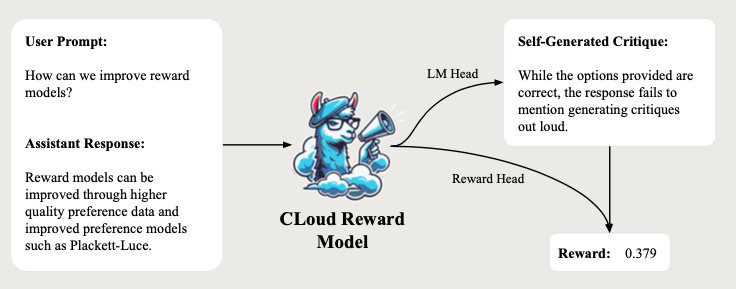

The Critique-out-Loud (CLoud) model, proposed by Ankner et al. (2024), represents an approach where reward models first generate natural language critiques of the LLM response. Then, the user’s prompt, the LLM’s response and the self-generated critique are evaluated to predict a scalar reward for the quality of the response. The key difference to the Synthetic Critiques model is that the CLoud reward model generates critiques itself rather than relying on external LLMs. CLoud reward models significantly outperformed traditional reward models as measured by the pairwise preference classification accuracy on complex reasoning tasks and challenging benchmarks like RewardBench (Lambert et al., 2024).
In addition to the base model and reward head, CLoud reward models preserve the language modeling head of the original pre-trained LLM. A powerful model like LLama-3.1-405B-Instruct is used to approximate human critiques. The training process involves training the base model and language modeling head to generate critiques via supervised fine-tuning on the human-approximated critiques, generating synthetic critiques from these fine-tuned models, and finally training a reward head based on the self-generated critiques.

By incorporating language generation to traditional reward models, the CLoud model combines the advantages of both traditional reward models and LLM-as-a-judge.
What’s next?
The convergence of LLM judges and reward modeling opens exciting new directions for AI alignment research. While traditional reward models rely heavily on human feedback, the integration of synthetic critiques and LLM-generated evaluations is showing promising results in both efficiency and performance. Recent work by Wang et al. (2024) demonstrates the potential of this approach - the paper states that their models, trained with a Relative Policy Optimization (RPO) objective, were three of the top four performing generative judge models on the RewardBench leaderboard as of September 20, 2024.
Key questions remain unexplored: How can we better leverage CoT reasoning in reward models? What architectures might optimally combine the benefits of traditional reward models with LLM judges? We look forward to exploring these as we continue to advance our LLM judge models. As research in this field accelerates, we expect innovative solutions to these challenges, potentially influencing how we train and align the next generation of language models.




